NEWS
2021.7.28
Toyota achieves Highest accuracy AI technology in Computer Vision Research with a paper accepted as a Grand champion of Video analysis competition in CVPR2021
- World's No. 1 accuracy in pixel-by-pixel detection and tracking technology for people and objects in video -


Toyota Motor Corporation
Data Analysis Group
InfoTech, Connected Advanced Development Div., Connected Company
Masayuki Yamazaki (Project Manager, R&D senior engineer)
Masao Yamanaka (Group Manager)
Toyota Motor Corporation has developed an image recognition AI technology for object detection, segmentation and tracking in video. Our technology was accepted by CVPR2021, the highest authority conference in the field of computer vision and video processing technology and artificial intelligence, and was presented on June 20, 2021. Within the conference, a video object recognition technology competition was held, and we won 1st place out of 331 entries. The technology is an application of the developed platform and techniques built and accumulated through five years of mid- to long-term research and development and multiple field demonstrations by our AI department with the scrum system of Logixsquare and Cybercore (co-authors) to YouTube video analysis.
Since the appearance of neural networks for still images in 2017, pixel-by-pixel video object recognition technology has attracted the attention of research institutes and companies, and there is a global development race in the world. This technology is called Instance Segmentation, and has many applications as a highly versatile fundamental technology (see examples below).
- - Scene Understanding for ADAS,In-Cabin of Vehicle, etc.
- - Sensing Human behavior and objectstatus in Plant and Production factory, Agriculture, Security, Robotics
- - Video analysis and Summarizationtechnology in Video streaming and Video management system
- - Video applications such as photo /video editing, Background composition, AR / VR / XR, etc.
We are very honored that our technology presented here has recorded the world's highest accuracy in computer vision field and has been accepted for CVPR2021, which is the result of our steady research and development. Through our research and development, we continue to contribute to the safety and convenience of the mobility society, the realization of a decarbonized society, and the development of a sustainable society.
- Key technologies -
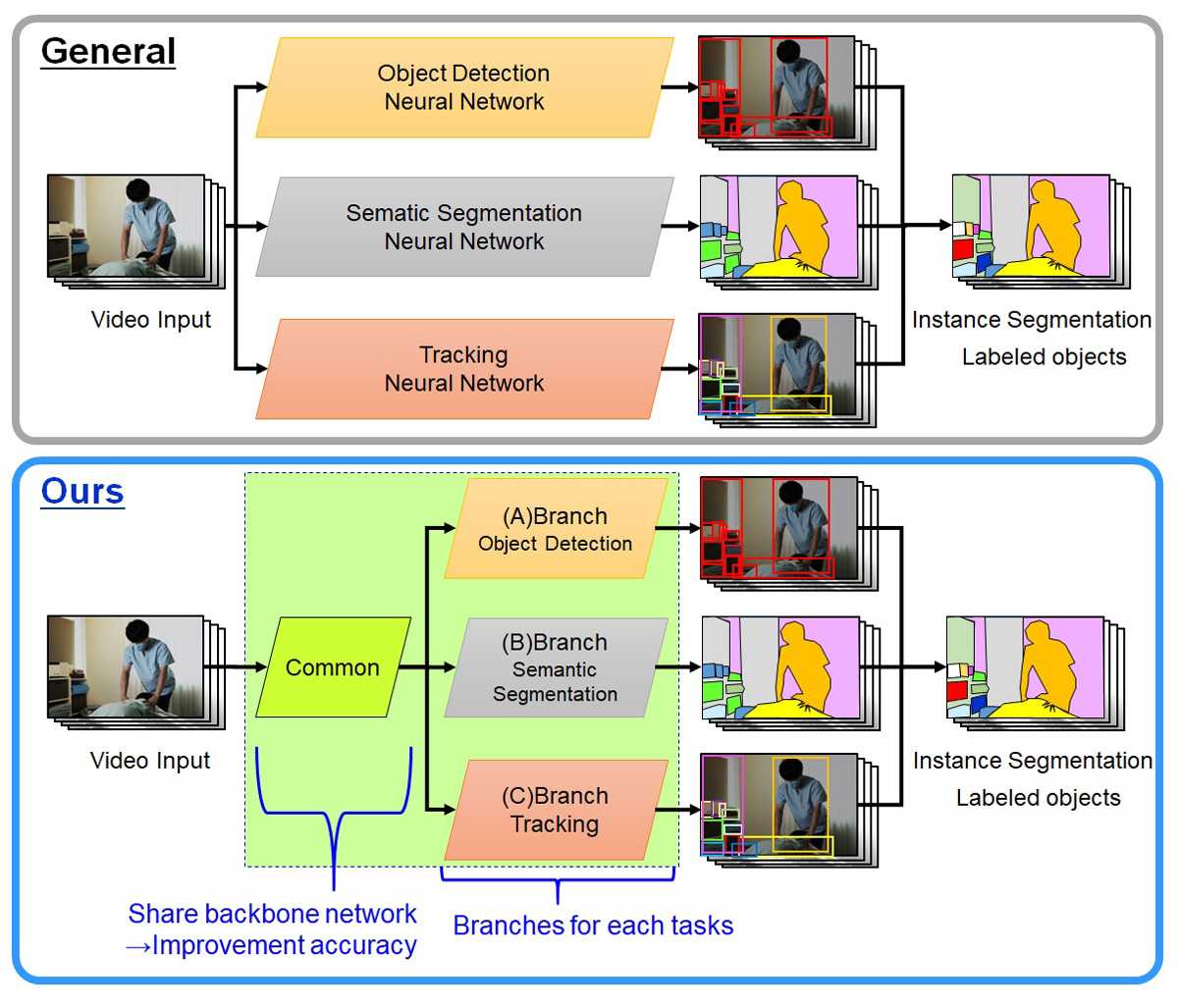
We have developed an algorithm that improves recognition accuracy by a comprehensive video analysis method of three different tasks (1) object detection, (2) segmentation, and (3) tracking while referring to each other in the machine learning phase. Using neural networks, we are able to handle the variety of situations and vast amount of information that video has to offer.
In general, a basic neural network consists of 1 neural network for 1 task. In our method, it is composed single network part likes a tree trunk for the operations common to the 3 tasks, and 3 network parts like a tree branch for several tasks.
This technology is called “Multi-task network”, require more difficult to machine learning, many previous studies have used more complex methods. Our method has a simple architecture and a light weight approach for embedded small IoT devices and efficient cloud computing with devising the machine learning method such as time-series and objectness.
Training Strategy
- (A) Design a neural network as the trunk of a tree for the object detection task on still images, and train the correct labels previously annotated to the dataset.
- (B) Design a small-scale neural network as a branch of a tree for the segmentation task, add it to (A), and train it in the same way as in (A).
- (C) As in (B), design a small-scale neural network as another branch of the tree for the tracking task, added to (B), and train it.
Scheme Points
- (1) We adjusted the architecturelevel of the neural network so that the learning converges stably bygradually expanding the tasks as described in (A) → (B) → (C) above.
- (2) We applied a learning theorycalled semi-supervised learning to a real dataset. Specifically, weextracted common parts in the correct labeling rules of the open dataset,which is widely used in general, and the production dataset, and trainedthem in addition to the training data in (A) and (B) to improve therecognition accuracy for each still image.
- (3) In addition to learning trackingin the forward direction of the time axis, we have also learned trackingin the reverse direction (time rewind direction) to improve the accuracyof tracking and situations where people and objects overlap, therebyincreasing the recognition accuracy in video.
Achievement
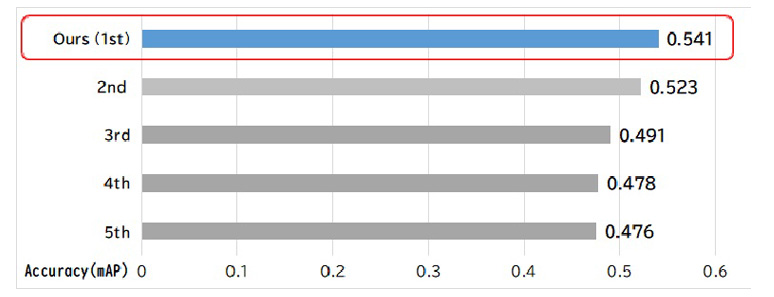
We applied our presented method to the subject of the competition (YouTube-VIS 2021 version dataset), and recorded a score of 0.541 points in mAP (mean Average Precision), and won the 1st place out of 331 entries in the Video Instance Segmentation category. By using YouTube videos of common and diverse situations as the subject, we proved the versatility of our presented technology.
- - Presented day: June 20th, 2021
- - Conference: CVPR2021(IEEE/CVF Computer Vision and Pattern Recognition)
- - Title:1st Place Solution for YouTubeVOS Challenge 2021:Video Instance Segmentation
Thank you.
■Introduction Our R&D group
Data Analysis Group, InfoTech, Connected Advanced Development Div.
Our group is developing actual systems and services based on machine learning using image data obtained from embedded cameras inside and outside the vehicle and vehicle behavior (CAN) data. For example, our technology for road obstacle detection based on image data of the embedded cameras was ranked 1st in the world in a quantitative evaluation using public datasets, and was accepted to ACCV2020, one of the most important conferences in computer vision. Also, our technology for detecting and tracking people and objects in videos pixel by pixel won 1st place in the world in a competition for object recognition technology, and was adopted for CVPR2021, one of the most important conferences in computer vision.
In addition, our group is parallel developing on deploying some edge devices (i.e. Xavier, Google Edge TPU) using network compression technologies (quantization, pruning, distillation), and on distributed and parallel processing using middleware such as Kubernetes (for the purpose of operating the technology in the cloud) to release our planned new services and architectures.
In this way, we believe the strength of our group is that we are able to conduct research and development activities that cover a wide range of areas, from upstream design as our specialty areas to operation as collaboration areas, in order to realize a certain system or service.
Research and development in data analysis techniques based on machine learning, especially in image processing, has already resulted in the existence of numerous public data sets. Also, the competitions using these public datasets are regularly held, and the world's leading research institutions and universities and other public research institutions including big tech companies called "GAFAM," are competing in the world. However, it is not necessarily the case that the world's No. 1 AI-related technology obtained in this competition will directly lead to good user experiences for our customers. Because, while these AI-related technologies can perform very well in certain limited conditions, they generally have low generalization performance and are not practical to use. In other words, in many cases it strongly depends on the public dataset and high computational cost is significant in real use cases. Therefore, researchers and developers have to extract the "essence" of the AI-related technologies and repeatedly "kaizen" (optimize) to fit our customer’s use cases.
We believe that the moment when the knowledge and know-how gained through this very unique and steady process is reflected in actual systems and services, and leads to good user experiences " satisfactory, comfortable, and enjoyable" for our customers, is our moment of fulfillment (the real thrill/exciting) and our motivation to continue research and development.
■Cool Career Opportunities/Hiring
The business domain of data analysis using machine learning and image recognition is one of our focus areas. Along with the improvement of ICT and cloud technologies and in-vehicle cameras, our scope of application is expanding from vehicles and vehicles to urban development and mobility services.
Our group is looking for new staffs who can enhance their expertise in a particular technical area (AI-related technology) while also expand (or try to expand) coverage and collaboration area based on that technical area.
For example, one of the projects in which our group is involved is the advanced development of a crew-less system (i.e. automatic door opening/closing, departure judgment) for an automated shuttle bus which is called e-Palette with MaaS (Mobility as a Service). The elemental technologies for realizing this system include human detection from images, posture estimation, and abnormal behavior detection. A number of promising methods have already been proposed in the research field of computer vision for these elemental technologies. However, simply combining these elemental technologies is not enough to make a system. In other words, a mechanism is needed to dynamically allocate the functions of these elemental technologies, sometimes on the cloud side, sometimes on the edge side, depending on the situation of the vehicle (i.e. driving, getting in and out, stopping).
With customers value, our mission is to maximize user experiences of our customers by building our "optimal architecture" hat incorporate the essence of these technologies and the needs of our customers, while keeping abreast of the latest research on elemental technologies.